Finding bottlenecks with RabbitMQ 3.3
One of the goals for RabbitMQ 3.3 was that you should be able to find bottlenecks in running systems more easily. Older versions of RabbitMQ let you see that you were rate-limited but didn't easily let you see why. In this blog post we'll talk through some of the new performance indicators in version 3.3.
Understanding flow control
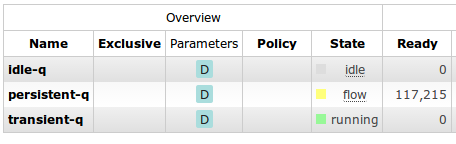
Since the introduction of flow control in RabbitMQ 2.8.0, you've been able to see when a connection has gone into the flow-controlled state. This (roughly) means that the client is being rate-limited; it would like to publish faster but the server can't keep up. Of course, the next question you'll want to ask is "why?".
The flow control mechanism has always extended throughout the server; not just connections but channels and queues can be in the flow-control state, meaning that they would like to publish messages faster, but something ahead of them can't keep up. So to make sense of the new flow control information you need to know that a component will go into flow control if anything it is publishing to is a bottleneck - or is in flow control itself. The order that components handle messages on their way into the server is:
Network
↓
Connection process - AMQP parsing, channel multiplexing
↓
Channel process - routing, security, coordination
↓
Queue process - in-memory messages, persistent queue indexing
↓
Message store - message persistence
So what possible outcomes are there?
- A connection is in flow control, but none of its channels are - This means that one or more of the channels is the bottleneck; the server is CPU-bound on something the channel does, probably routing logic. This is most likely to be seen when publishing small transient messages.
- A connection is in flow control, some of its channels are, but none of the queues it is publishing to are - This means that one or more of the queues is the bottleneck; the server is either CPU-bound on accepting messages into the queue or I/O-bound on writing queue indexes to disc. This is most likely to be seen when publishing small persistent messages.
- A connection is in flow control, some of its channels are, and so are some of the queues it is publishing to - This means that the message store is the bottleneck; the server is I/O-bound on writing messages to disc. This is most likely to be seen when publishing larger persistent messages.
Consumer utilisation

So hopefully you can now better understand the performance of the publishing side of your server. So what about the consuming side? The flow control mechanism doesn't extend as far as consumers, but we do have a new metric to help you tell how hard your consumers are working.
That metric is consumer utilisation. The definition of consumer utilisation is the proportion of time that a queue's consumers could take new messages. It's thus a number from 0 to 1, or 0% to 100% (or N/A if the queue has no consumers). So if a queue has a consumer utilisation of 100% then it never needs to wait for its consumers; it's always able to push messages out to them as fast as it can.
If its utilisation is less than 100% then this implies that its consumers are sometimes not able to take messages. Network congestion can limit the utilisation you can achieve, or low utilisation can be due to the use of too low a prefetch limit, leading to the queue needing to wait while the consumer processes messages until it can send out more.
The following table shows some approximate values for consumer utilisation I observed when consuming tiny messages over localhost with a single consumer:
| Prefetch limit | Consumer utilisation |
|---|---|
| 1 | 14% |
| 3 | 25% |
| 10 | 46% |
| 30 | 70% |
| 1000 | 74% |
You can see that the utilisation increases with the prefetch limit until we reach a limit of about 30. After that the network bandwidth limitation starts to dominate and increasing the limit has no further benefit. So you can see that consumer utilisation is an easy way to monitor the performance of our consumers.
Learn More
Process finished with exit code 0